

Personal Project
3 Weeks
Ananay Gupta


The goal of my project is to make creative expression and collaboration more accessible to Blind and Low Vision (BLV) users by developing new tools for artistic creation and effective communication. This project aims to empower BLV users with greater agency and opportunities to create, modify, and deeply engage with generated digital art, while also acting as a medium for visual communication. By exploring how I can leverage current AI models to create these tools, I seek to bridge the gap between visual and non-visual experiences, enabling inclusive and meaningful artistic collaboration.
The project is aimed at creating accessible tools for Blind and Low Vision (BLV) users to express creativity and collaborate through digital art. It features a digital canvas with real-time feedback and AI-powered tools to transform sketches into detailed, realistic visualizations
BLV users face significant barriers to artistic creation and communication due to the lack of tactile feedback and inclusive tools in digital art platforms. This project bridges the gap, offering spatial, emotional, and contextual support to empower BLV users in both creating and sharing their artwork.
The Accessible Canvas promotes inclusivity in creative expression, enabling BLV users to communicate artistic ideas to sighted audiences and fostering collaboration. By combining AI with accessibility, it creates opportunities for BLV users to engage deeply with art and share their unique perspectives.
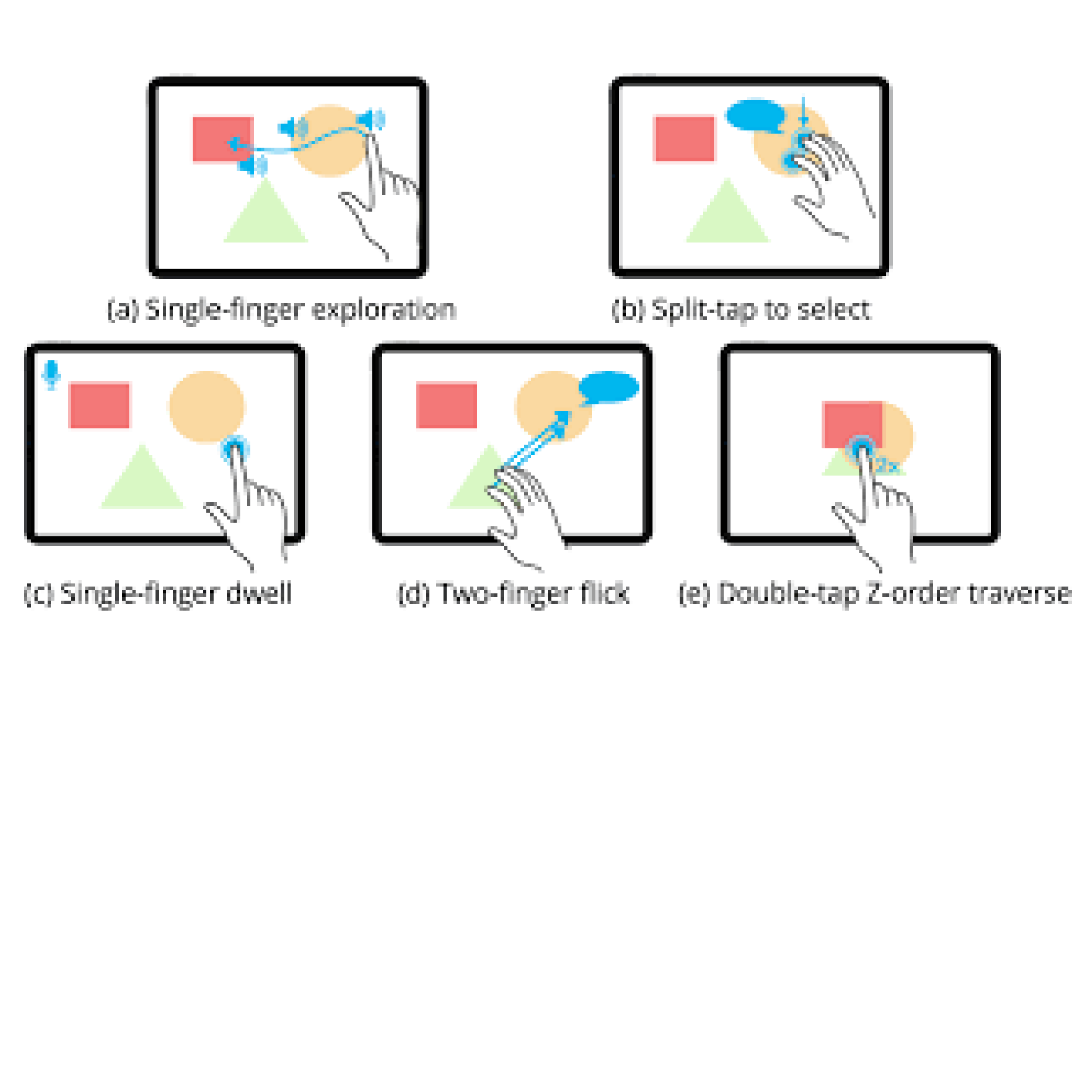
I am developing the digital canvas and designing its feedback system, ensuring it provides spatial guidance for BLV users. I am also integrating AI tools for generating detailed images and descriptive feedback, as well as building an interactive system for follow-up questions to enhance user trust and engagement.

The user can sketch with spatial feedback and enter an image prompt describing the image

An AI feature that transforms user sketches and prompts into detailed, realistic visualizations.

Asking follow-up questions, ensuring alignment with their vision and enhancing trust
How can we leverage AI to assist BLV individuals in creating and communicating visual ideas?
An accessible digital art board for BLV users to create visual content developed at University of Washinton.

Uses AI to turn simple brushstrokes into realistic landscape images.

Touch Graphics, a company that makes products that communicate spatial information through sense of touch,

An experimental project by google exploring Auditory feedback with drawing

Themes
Digital drawing platforms.
AI image generation tools
Preferences for image descriptions.
Activity
Sketch an image of "a dog playing with a ball" and describe it.
The image shows a sketch drawn by a Blind participant


Digital Drawing Platforms
Combine locating coordinates on the canvas with auditory feedback
Provide feedback on the relationship between objects, such as their relative positioning and distances.
Explore methods to include tactile inputs using the keyboard and mouse.

AI Image Generation
Provide a way for BLV users to validate whether the generated image matches their prompts and sketches.
Enable users to include additional context or details to improve the quality of the generated image.

AI Image Description
Implement a feature that allows for follow-up questions, enabling users to gain more detailed insights.
Ensure that descriptions include spatial relationships and contextual details.
Keep descriptions flexible to allow for individual interpretation

Initially, I assumed that describing the image by explaining the position of subjects and objects within four quadrants, and explaining images based on the emotions intended by the user. However, after conducting preliminary research, I realized the need to include more detailed spatial relationships and contextual descriptions to better suit BLV users' needs. A key insight was to validate the generated image and allow people to ask follow-up questions about the image, I plan to explore this by using a visual question and answering model. I will also experiment with refining my image-to-text prompts to ensure they effectively describe the image.

P5.js
Used to create an Accessible canvas that gives auditory feedback

Image to Image Model (Sketch to Image)
TencentARC/t2i-adapter-sketch-sdxl-1.0 (Hugging Face)
Diffusion-based text-to-image generation model

Image to Text Model
Open AI 4o
To give a detailed description of subject and background of the generated image

Visual Question Answering Model
Salesforce/blip-vqa-capfilt-large(Hugging Face)
Allows the user to ask additional questions about the image to get a more detailed understanding

Unlearning:
This project taught me to unlearn assumptions about how they approach tasks. By listening and observing, I realized their strategies are far more diverse and nuanced than I initially thought, reinforcing the value of open-minded collaboration.
Communication:
Working with Blind and Low Vision individuals taught me the value of precise and spatially aware communication. Describing concepts required me to think beyond visual references, focusing on clear, positional, and tactile language.
Universal Design:
I learned the value of universal design, and I aim to take that forward by applying it in my future projects. By taking deliberate steps to create inclusive solutions, I can ensure my designs are accessible and meaningful for everyone.